- Change Makers
- Posts
- Is the World a Better Place Now Than Ever Before?
Is the World a Better Place Now Than Ever Before?
Will Caplan
January 7th, 2024 • Reading Time: 4 minutes
Is now the best time to be a human?
I think so.
This might be a bit of a controversial one to write, but it shouldn’t be. While of course there are deep-rooted, systemic, and significant problems globally, being a human on planet Earth today is the best possible time to do so in our species’ history.
Here are 3 graphs and explanations to hopefully prove it:
1. Poverty
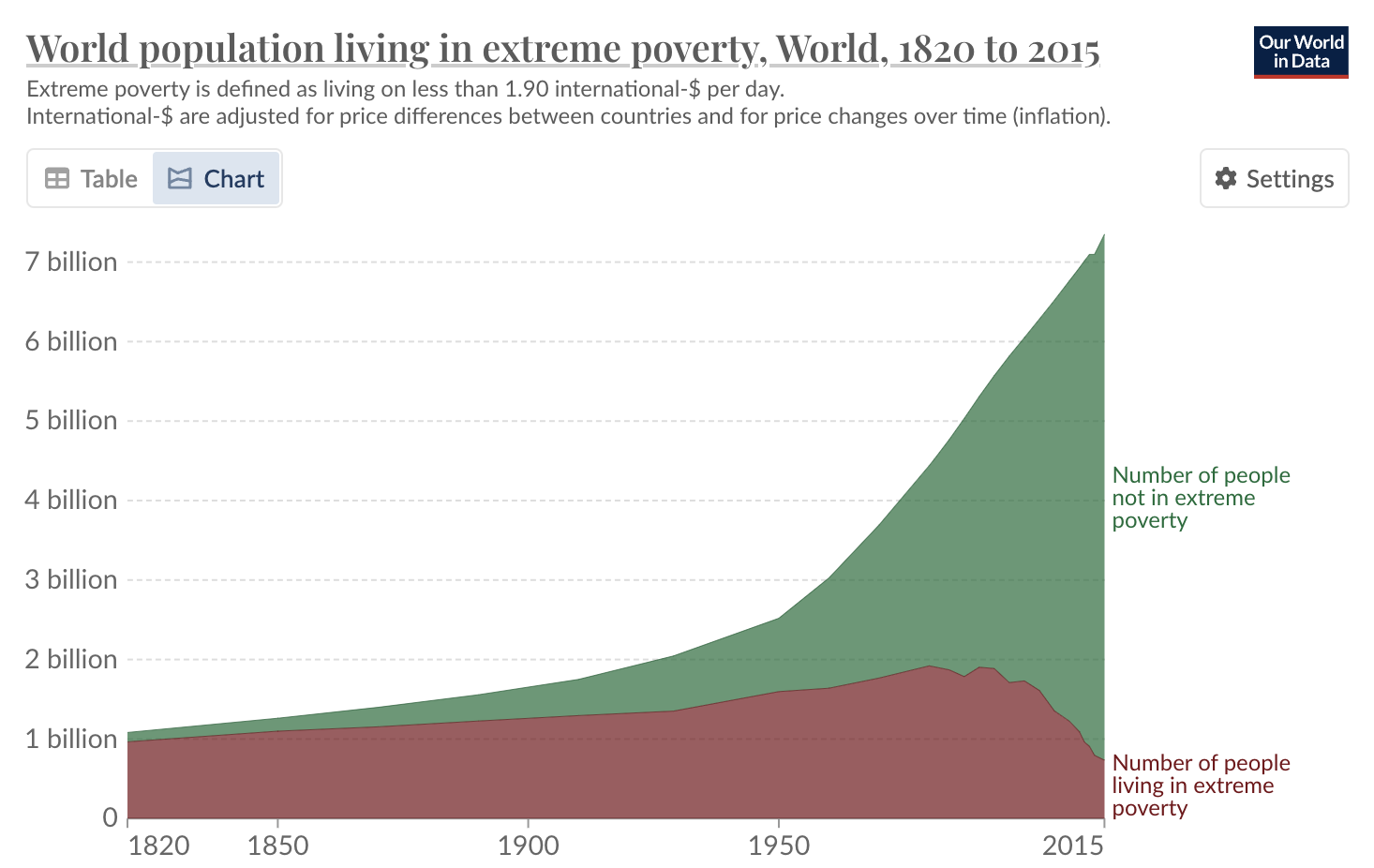
Now of course the Kings and Queens of yesteryear lived in the utmost opulence, but the vast majority of people lived in abject poverty, with a constant struggle for shelter, food and clothing. Nothing came easy.
Fast-forward a few hundred years, the proportion of those in poverty decreased enormously. Since the late 1900s, there has been a significant reduction in those living in extreme poverty. Despite the population increasing by 6 billion since 1820, the percentage of people living in extreme poverty has decreased by 250 million people.
2. Health
It’s not uncommon to hear people talking about the life expectancy of someone 300 years ago being significantly less than it is now. In medieval England, the life expectancy was just 51 years compared to 81 years today, so they would be right. However, this only tells a small bit of the story. Life expectancy figures were massively skewed by infant mortality being so incredibly high back in the day.
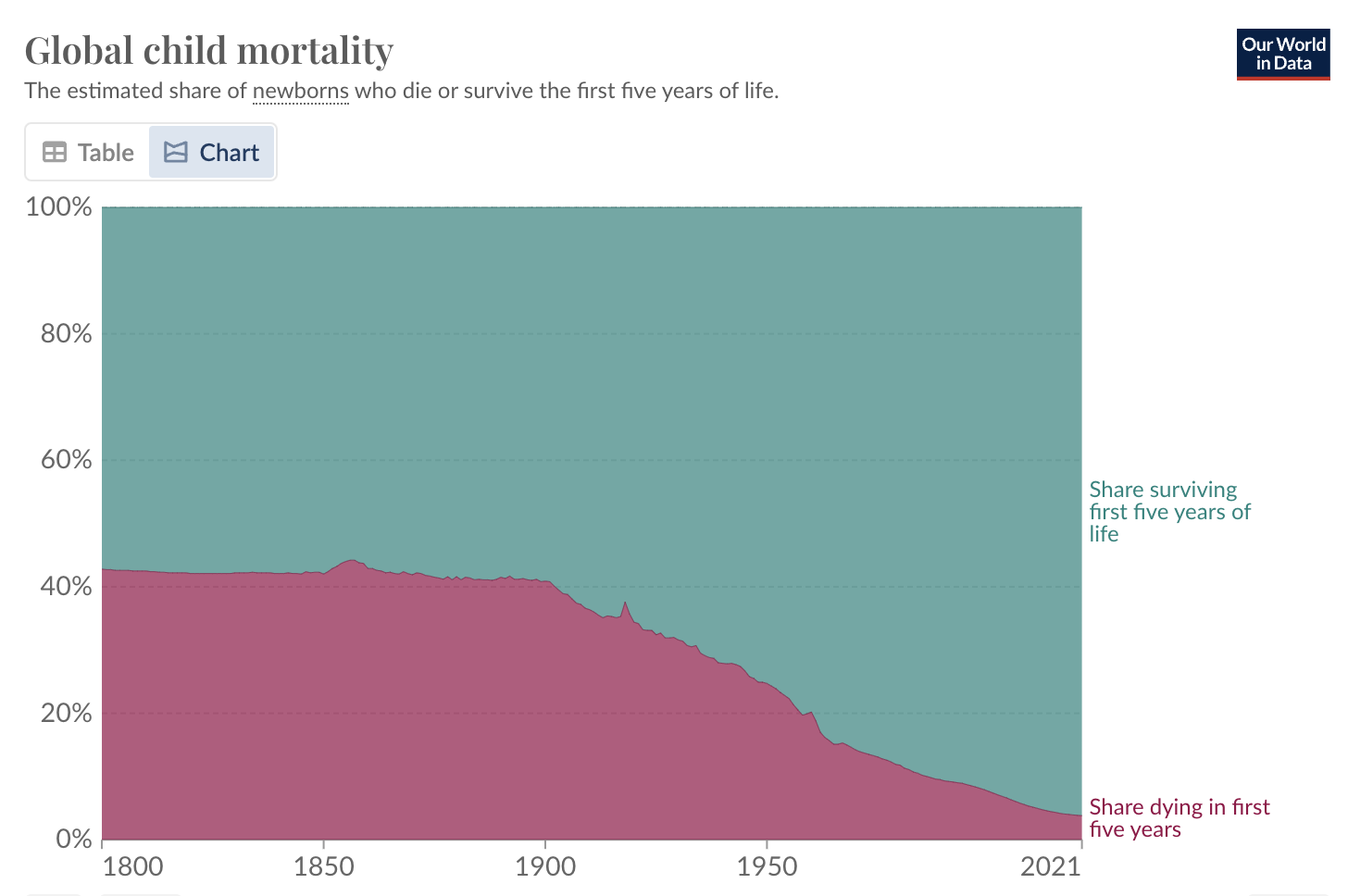
As you can see, in 1800, only 60% of infants made it past their 5th birthday. Now this is incredibly sad, but perhaps more happily I can report that by 2021 humanity had managed to cut this down to less than 5%.
Not only has child mortality reduced but the advancements in medical knowledge and technology are frankly mind-blowing. Treatments like bleeding (yeah literally just cutting you open and ‘bleeding you of your toxins/evil’) were common practice up until the end of the 19th century. In fact, the Bubonic plague, which I’m sure we all learned about at school, had a mortality rate of over 75%, but if it were to arise again it would be quite easily treated by modern antibiotics - just goes to show how far we’ve come.
3. Freedom
Now I’m not going to start waving an American flag in your face and chant, “USA! USA!”, but it’s my pretty strong belief that living in a democracy is a good thing (please don’t cancel me). The reasons why it’s preferential to live in a democracy are almost endless, but just to name a few: no nasty dictators (e.g. your Stalins or Pol Pots of this world), freedom of religion, freedom of the media, the protection of minorities and importantly free enterprise.
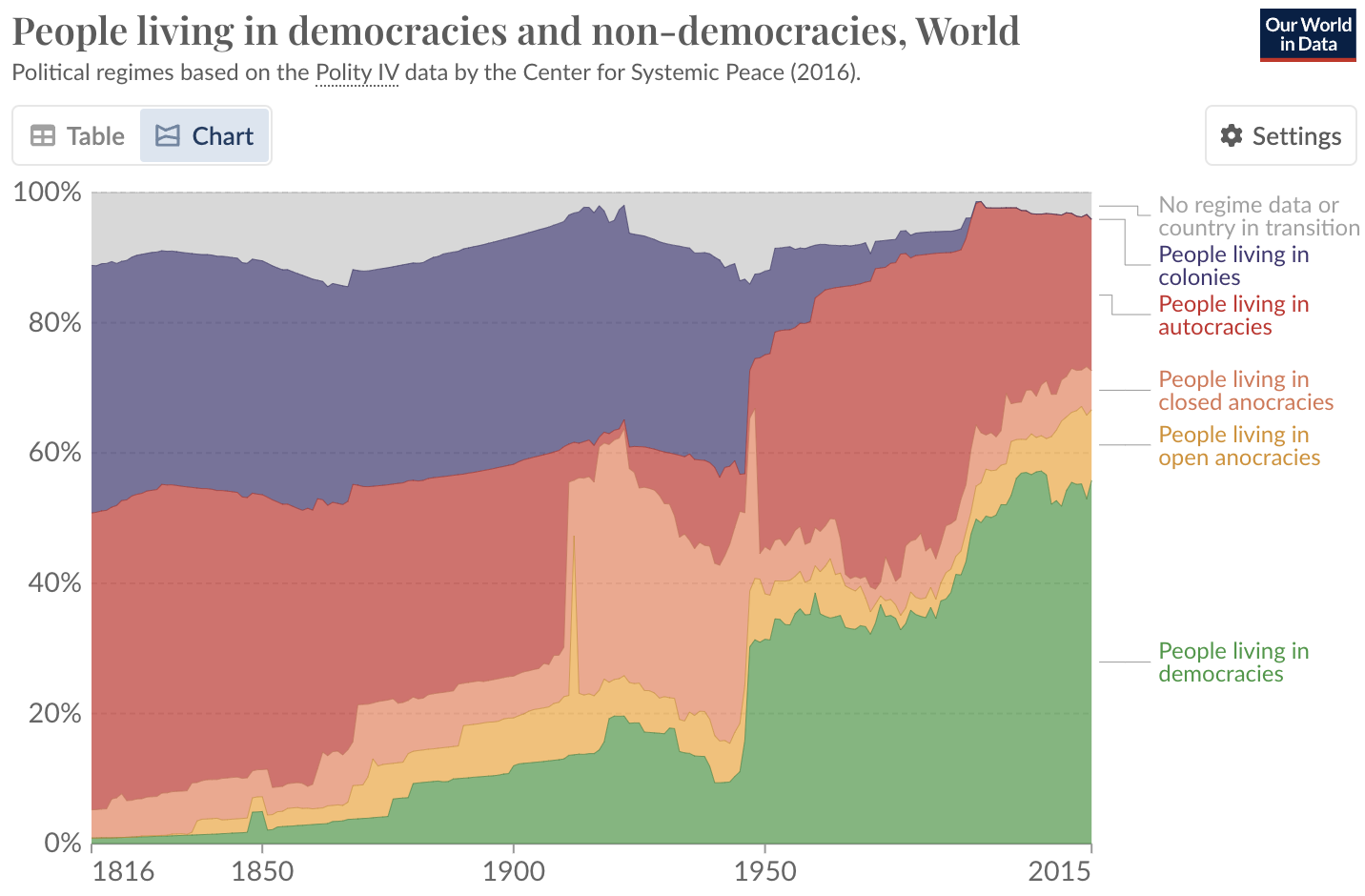
So a human in 2024 is likely to live longer, less likely to be in extreme poverty and live in a fairer and more equitable society than ever before.
We still have a lonnngggg way to go, but here is a “well done!” to our fellow humans of times gone past. You did leave the world a better place than you found it.
A big complicated legal battle
Before you all stop reading, this particular court case might dictate the future of content ownership in a world of AI-generated content and who makes billions from it.
What happened?
The New York Times is suing OpenAI.
Why does this matter?
I want to explain 2 things here:
How are the New York Times and ChatGPT connected?
Why is the copyright part interesting? (I am aware that I am one of few people to think Copyright is interesting, but I am going to persuade you)
Let’s start with 1. The way Large Language Models like ChatGPT are built is you take your AI cooking pot and it throw in a bunch of computing power (Graphics processing units) and then billions of gigabytes of training data. Training data is a scary phrase but essentially it is just things like news articles, tweets, blogs, quora posts, and Ask Jeeves responses (big up Jeeves). Any time someone wrote something on the internet, it might have been thrown into OpenAI’s cooking pot as a piece of training data.

Now you can see why a problem evolves here. The New York Times (NYT) has been publishing content since 1865. It has one of the largest repositories of written material of any private company and unlike Twitter, the quality of that material is high: it is thoughtful, well-rounded, and interesting. OpenAI, like a proud parent, wants ChatGPT to be thoughtful, well-rounded, and interesting. So it throws into its AI cooking pot a bunch of content from the NYT, without asking for it.
Ok, point 2 - why copyright matters here? Under copyright law, you have sections called Fair Use and Derivative Works. This outlines the reasonable use of an original piece of content and how you could create something new from it.
If ChatGPT just rewrote the NYT article word for word, this would be an obvious infringement of the law. Not Fair Use. If ChatGPT summarised the headline news articles, this would be more niche and might sit in the copyright grey zone. I am summarizing content I have read here, but I assume no one is going to sue me. Maybe a Derivative Work?
The interesting part here is that ChatGPT as a Large Language Model (LLM) is not summarising anything. LLMs ‘simply’ predict the next word in a sentence based on incredible amounts of training data. Training data itself is a misnomer as it allows the reader to infer that there is a database somewhere ChatGPT is drawing on. As Benedict Evans wrote in an essay last year “the training data is not the model. LLMs are not databases.”
The model has not stored the NYT articles anywhere and at best the NYT content makes up a fraction of a percent of ChatGPT training data.
What does this mean for the future?
Two things seem simultaneously true: the NYT has a dataset of content that is valuable to OpenAI, and how OpenAI has handled that content previously is a grey zone of the law that only the Supreme Court will have the final say over.
This presents a huge opportunity for companies like NYT as the value of creating these AI models, like chatGPT, might benefit the companies that have the training data rather than the model builders (OpenAI) themselves.
My bet is that LLMs, like ChatGPT, will become a commodity product and companies like OpenAI will have to pay to access rich datasets from the likes of The New York Times. OpenAI might just be in for a worse year than the last one.
Thanks so much for reading this far - we’d love to grow this newsletter so we are offering the following:
For every person you sign up, you get £0.50. Get 10 of your mates/colleagues to sign up we’ll send you £5.